Depuración de Workflows¶
Traducción asistida por IA - más información y sugerencias
La depuración es una habilidad fundamental que puede ahorrarte horas de frustración y ayudarte a convertirte en un desarrollador de Nextflow más eficaz. A lo largo de tu carrera, especialmente cuando estás comenzando, encontrarás errores mientras construyes y mantienes tus workflows. Aprender enfoques sistemáticos de depuración te ayudará a identificar y resolver problemas rápidamente.
Objetivos de aprendizaje¶
En esta misión secundaria, exploraremos técnicas sistemáticas de depuración para workflows de Nextflow:
- Depuración de errores de sintaxis: Uso efectivo de las funciones del IDE y los mensajes de error de Nextflow
- Depuración de canales: Diagnóstico de problemas en el flujo de datos y en la estructura de los canales
- Depuración de procesos: Investigación de fallos de ejecución y problemas de recursos
- Herramientas de depuración integradas: Aprovechamiento del modo de vista previa, la ejecución stub y los directorios de trabajo de Nextflow
- Enfoques sistemáticos: Una metodología de cuatro fases para una depuración eficiente
Al finalizar, tendrás una metodología de depuración sólida que transforma los mensajes de error frustrantes en hojas de ruta claras hacia las soluciones.
Requisitos previos¶
Antes de comenzar esta misión secundaria, debes:
- Haber completado el tutorial Hello Nextflow o un curso equivalente para principiantes.
- Sentirte cómodo/a usando los conceptos y mecanismos básicos de Nextflow (procesos, canales, operadores)
Opcional: Recomendamos completar primero la misión secundaria IDE Features for Nextflow Development. Esta cubre de manera exhaustiva las funciones del IDE que apoyan la depuración (resaltado de sintaxis, detección de errores, etc.), que usaremos ampliamente aquí.
0. Primeros pasos¶
Abrir el codespace de capacitación¶
Si aún no lo has hecho, asegúrate de abrir el entorno de capacitación como se describe en la Configuración del entorno.
![]()
Moverse al directorio del proyecto¶
Vamos a movernos al directorio donde se encuentran los archivos de este tutorial.
Puedes configurar VSCode para que se enfoque en este directorio:
Revisar los materiales¶
Encontrarás un conjunto de workflows de ejemplo con varios tipos de errores que usaremos para practicar:
Contenido del directorio
.
├── bad_bash_var.nf
├── bad_channel_shape.nf
├── bad_channel_shape_viewed_debug.nf
├── bad_channel_shape_viewed.nf
├── bad_number_inputs.nf
├── badpractice_syntax.nf
├── bad_resources.nf
├── bad_syntax.nf
├── buggy_workflow.nf
├── data
│ ├── sample_001.fastq.gz
│ ├── sample_002.fastq.gz
│ ├── sample_003.fastq.gz
│ ├── sample_004.fastq.gz
│ ├── sample_005.fastq.gz
│ └── sample_data.csv
├── exhausted.nf
├── invalid_process.nf
├── missing_output.nf
├── missing_software.nf
├── missing_software_with_stub.nf
├── nextflow.config
└── no_such_var.nf
Estos archivos representan escenarios de depuración comunes que encontrarás en el desarrollo del mundo real.
Revisar la tarea¶
Tu desafío es ejecutar cada workflow, identificar el o los errores y corregirlos.
Para cada workflow con errores:
- Ejecuta el workflow y observa el error
- Analiza el mensaje de error: ¿qué te está diciendo Nextflow?
- Localiza el problema en el código usando las pistas proporcionadas
- Corrige el error y verifica que tu solución funcione
- Restablece el archivo antes de pasar a la siguiente sección (usa
git checkout <filename>)
Los ejercicios progresan desde errores de sintaxis simples hasta problemas de ejecución más sutiles. Las soluciones se discuten en línea, pero intenta resolver cada uno por tu cuenta antes de leer más adelante.
Lista de verificación de preparación¶
¿Crees que estás listo/a para comenzar?
- Entiendo el objetivo de este curso y sus requisitos previos
- Mi codespace está en funcionamiento
- He configurado mi directorio de trabajo correctamente
- Entiendo la tarea
Si puedes marcar todas las casillas, estás listo/a para comenzar.
1. Errores de Sintaxis¶
Los errores de sintaxis son el tipo más común de error que encontrarás al escribir código Nextflow. Ocurren cuando el código no se ajusta a las reglas de sintaxis esperadas del DSL de Nextflow. Estos errores impiden que tu workflow se ejecute por completo, por lo que es importante aprender a identificarlos y corregirlos rápidamente.
1.1. Llaves faltantes¶
Uno de los errores de sintaxis más comunes, y a veces uno de los más complejos de depurar, es el de llaves faltantes o no coincidentes.
Comencemos con un ejemplo práctico.
Ejecutar el pipeline¶
Salida del comando
Elementos clave de los mensajes de error de sintaxis:
- Archivo y ubicación: Muestra qué archivo y línea/columna contienen el error (
bad_syntax.nf:24:1) - Descripción del error: Explica qué encontró el analizador que no esperaba (
Unexpected input: '<EOF>') - Indicador EOF: El mensaje
<EOF>(End Of File) indica que el analizador llegó al final del archivo mientras aún esperaba más contenido - una señal clásica de llaves sin cerrar
Revisar el código¶
Ahora, examinemos bad_syntax.nf para entender qué está causando el error:
Para este ejemplo hemos dejado un comentario para mostrarte dónde está el error. La extensión de Nextflow para VSCode también debería darte algunas pistas sobre qué podría estar mal, poniendo la llave no coincidente en rojo y resaltando el final prematuro del archivo:
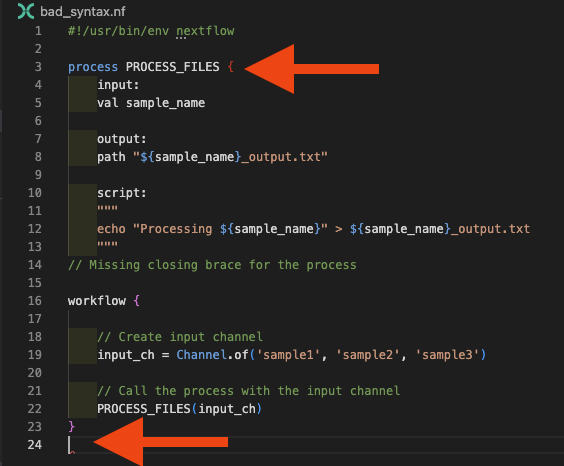
Estrategia de depuración para errores de llaves:
- Usa la coincidencia de llaves de VS Code (coloca el cursor junto a una llave)
- Revisa el panel de Problemas para mensajes relacionados con llaves
- Asegúrate de que cada
{de apertura tenga su correspondiente}de cierre
Corregir el código¶
Reemplaza el comentario con la llave de cierre faltante:
Ejecutar el pipeline¶
Ahora ejecuta el workflow nuevamente para confirmar que funciona:
Salida del comando
1.2. Uso de palabras clave o directivas de proceso incorrectas¶
Otro error de sintaxis común es una definición de proceso inválida. Esto puede ocurrir si olvidas definir los bloques requeridos o usas directivas incorrectas en la definición del proceso.
Ejecutar el pipeline¶
Salida del comando
N E X T F L O W ~ version 25.10.2
Launching `invalid_process.nf` [nasty_jepsen] DSL2 - revision: da9758d614
Error invalid_process.nf:3:1: Invalid process definition -- check for missing or out-of-order section labels
│ 3 | process PROCESS_FILES {
│ | ^^^^^^^^^^^^^^^^^^^^^^^
│ 4 | inputs:
│ 5 | val sample_name
│ 6 |
╰ 7 | output:
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Revisar el código¶
El error indica una "definición de proceso inválida" y muestra el contexto alrededor del problema. Al mirar las líneas 3-7, podemos ver inputs: en la línea 4, que es el problema. Examinemos invalid_process.nf:
Al mirar la línea 4 en el contexto del error, podemos identificar el problema: estamos usando inputs en lugar de la directiva correcta input. La extensión de Nextflow para VSCode también marcará esto:
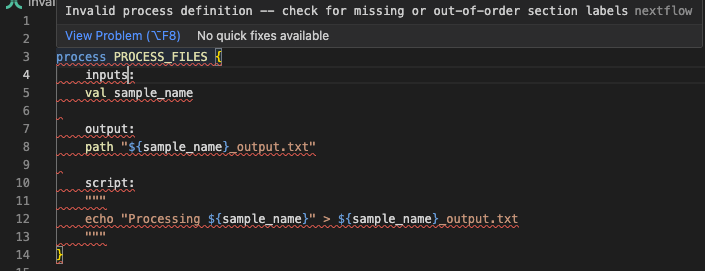
Corregir el código¶
Reemplaza la palabra clave incorrecta con la correcta consultando la documentación:
Ejecutar el pipeline¶
Ahora ejecuta el workflow nuevamente para confirmar que funciona:
Salida del comando
1.3. Uso de nombres de variables incorrectos¶
Los nombres de variables que uses en tus bloques de script deben ser válidos, derivados ya sea de las entradas o del código Groovy insertado antes del script. Pero cuando estás manejando complejidad al inicio del desarrollo de un pipeline, es fácil cometer errores en el nombramiento de variables, y Nextflow te lo hará saber rápidamente.
Ejecutar el pipeline¶
Salida del comando
N E X T F L O W ~ version 25.10.2
Launching `no_such_var.nf` [gloomy_meninsky] DSL2 - revision: 0c4d3bc28c
Error no_such_var.nf:17:39: `undefined_var` is not defined
│ 17 | echo "Using undefined variable: ${undefined_var}" >> ${output_pref
╰ | ^^^^^^^^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
El error se detecta en tiempo de compilación y apunta directamente a la variable no definida en la línea 17, con un acento circunflejo que indica exactamente dónde está el problema.
Revisar el código¶
Examinemos no_such_var.nf:
El mensaje de error indica que la variable no está reconocida en la plantilla del script, y ahí lo tienes: deberías poder ver ${undefined_var} usado en el bloque de script, pero no definido en ningún otro lugar.
Corregir el código¶
Si obtienes un error de 'No such variable', puedes corregirlo ya sea definiendo la variable (corrigiendo los nombres de las variables de entrada o editando el código Groovy antes del script), o eliminándola del bloque de script si no es necesaria:
Ejecutar el pipeline¶
Ahora ejecuta el workflow nuevamente para confirmar que funciona:
Salida del comando
1.4. Uso incorrecto de variables Bash¶
Al comenzar con Nextflow, puede ser difícil entender la diferencia entre las variables de Nextflow (Groovy) y las de Bash. Esto puede generar otra forma del error de variable incorrecta que aparece al intentar usar variables en el contenido Bash del bloque de script.
Ejecutar el pipeline¶
Salida del comando
N E X T F L O W ~ version 25.10.2
Launching `bad_bash_var.nf` [infallible_mandelbrot] DSL2 - revision: 0853c11080
Error bad_bash_var.nf:13:42: `prefix` is not defined
│ 13 | echo "Processing ${sample_name}" > ${prefix}.txt
╰ | ^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Revisar el código¶
El error apunta a la línea 13 donde se usa ${prefix}. Examinemos bad_bash_var.nf para ver qué está causando el problema:
| bad_bash_var.nf | |
|---|---|
En este ejemplo, estamos definiendo la variable prefix en Bash, pero en un proceso de Nextflow la sintaxis $ que usamos para referenciarlo (${prefix}) se interpreta como una variable Groovy, no Bash. La variable no existe en el contexto Groovy, por lo que obtenemos un error de 'no such variable'.
Corregir el código¶
Si quieres usar una variable Bash, debes escapar el signo de dólar de esta manera:
| bad_bash_var.nf | |
|---|---|
Esto le indica a Nextflow que interprete esto como una variable Bash.
Ejecutar el pipeline¶
Ahora ejecuta el workflow nuevamente para confirmar que funciona:
Salida del comando
Variables Groovy vs Bash
Para manipulaciones simples de variables como concatenación de strings u operaciones de prefijo/sufijo, generalmente es más legible usar variables Groovy en la sección del script en lugar de variables Bash en el bloque de script:
Este enfoque evita la necesidad de escapar los signos de dólar y hace que el código sea más fácil de leer y mantener.
1.5. Sentencias fuera del bloque workflow¶
La extensión de Nextflow para VSCode resalta problemas con la estructura del código que causarán errores. Un ejemplo común es definir canales fuera del bloque workflow {} - esto ahora se aplica como un error de sintaxis.
Ejecutar el pipeline¶
Salida del comando
N E X T F L O W ~ version 25.10.2
Launching `badpractice_syntax.nf` [intergalactic_colden] DSL2 - revision: 5e4b291bde
Error badpractice_syntax.nf:3:1: Statements cannot be mixed with script declarations -- move statements into a process or workflow
│ 3 | input_ch = channel.of('sample1', 'sample2', 'sample3')
╰ | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
El mensaje de error indica claramente el problema: las sentencias (como las definiciones de canales) no pueden mezclarse con las declaraciones del script fuera de un bloque workflow o process.
Revisar el código¶
Examinemos badpractice_syntax.nf para ver qué está causando el error:
La extensión de VSCode también resaltará la variable input_ch como definida fuera del bloque workflow:
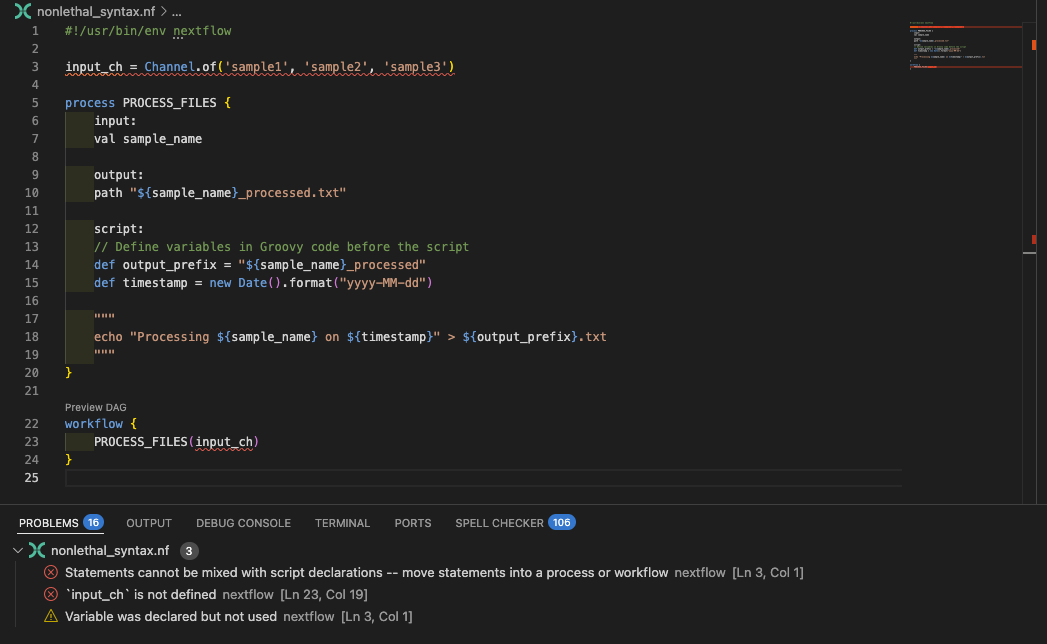
Corregir el código¶
Mueve la definición del canal dentro del bloque workflow:
Ejecutar el pipeline¶
Ejecuta el workflow nuevamente para confirmar que la corrección funciona:
Salida del comando
Mantén tus canales de entrada definidos dentro del bloque workflow y, en general, sigue cualquier otra recomendación que haga la extensión.
Conclusión¶
Puedes identificar y corregir sistemáticamente los errores de sintaxis usando los mensajes de error de Nextflow y los indicadores visuales del IDE. Los errores de sintaxis comunes incluyen llaves faltantes, palabras clave de proceso incorrectas, variables no definidas y uso incorrecto de variables Bash vs. Nextflow. La extensión de VSCode ayuda a detectar muchos de estos antes de la ejecución. Con estas habilidades de depuración de sintaxis en tu arsenal, podrás resolver rápidamente los errores de sintaxis de Nextflow más comunes y pasar a abordar problemas de ejecución más complejos.
¿Qué sigue?¶
Aprende a depurar errores de estructura de canal más complejos que ocurren incluso cuando la sintaxis es correcta.
2. Errores de Estructura de Canal¶
Los errores de estructura de canal son más sutiles que los errores de sintaxis porque el código es sintácticamente correcto, pero las formas de los datos no coinciden con lo que esperan los procesos. Nextflow intentará ejecutar el pipeline, pero puede encontrar que el número de entradas no coincide con lo que espera y fallar. Estos errores típicamente solo aparecen en tiempo de ejecución y requieren una comprensión del flujo de datos a través de tu workflow.
Depuración de canales con .view()
A lo largo de esta sección, recuerda que puedes usar el operador .view() para inspeccionar el contenido del canal en cualquier punto de tu workflow. Esta es una de las herramientas de depuración más poderosas para entender los problemas de estructura de canal. Exploraremos esta técnica en detalle en la sección 2.4, pero siéntete libre de usarla mientras trabajas en los ejemplos.
2.1. Número incorrecto de canales de entrada¶
Este error ocurre cuando pasas un número diferente de canales al que espera un proceso.
Ejecutar el pipeline¶
Salida del comando
N E X T F L O W ~ version 25.10.2
Launching `bad_number_inputs.nf` [happy_swartz] DSL2 - revision: d83e58dcd3
Error bad_number_inputs.nf:23:5: Incorrect number of call arguments, expected 1 but received 2
│ 23 | PROCESS_FILES(samples_ch, files_ch)
╰ | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Revisar el código¶
El mensaje de error indica claramente que la llamada esperaba 1 argumento pero recibió 2, y apunta a la línea 23. Examinemos bad_number_inputs.nf:
Deberías ver la llamada a PROCESS_FILES con un número incorrecto de argumentos, suministrando múltiples canales de entrada cuando el proceso solo define uno. La extensión de VSCode también subrayará la llamada al proceso en rojo y mostrará un mensaje de diagnóstico al pasar el cursor:
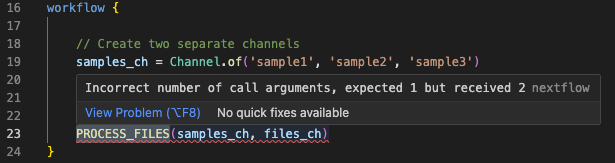
Corregir el código¶
Para este ejemplo específico, el proceso espera un solo canal y no requiere el segundo canal, por lo que podemos corregirlo pasando solo el canal samples_ch:
Ejecutar el pipeline¶
Salida del comando
Más comúnmente que en este ejemplo, podrías agregar entradas adicionales a un proceso y olvidar actualizar la llamada al workflow en consecuencia, lo que puede llevar a este tipo de error. Afortunadamente, este es uno de los errores más fáciles de entender y corregir, ya que el mensaje de error es bastante claro sobre la discrepancia.
2.2. Agotamiento de canal (el proceso se ejecuta menos veces de lo esperado)¶
Algunos errores de estructura de canal son mucho más sutiles y no producen ningún error en absoluto. Probablemente el más común de estos refleja un desafío que enfrentan los nuevos usuarios de Nextflow al entender que los queue channels pueden agotarse y quedarse sin elementos, lo que significa que el workflow termina prematuramente.
Ejecutar el pipeline¶
Salida del comando
N E X T F L O W ~ version 25.10.2
Launching `exhausted.nf` [extravagant_gauss] DSL2 - revision: 08cff7ba2a
executor > local (1)
[bd/f61fff] PROCESS_FILES (1) [100%] 1 of 1 ✔
¡Este workflow se completa sin error, pero solo procesa una muestra!
Revisar el código¶
Examinemos exhausted.nf para ver si eso es correcto:
El proceso solo se ejecuta una vez en lugar de tres veces porque el canal reference_ch es un queue channel que se agota después de la primera ejecución del proceso. Cuando un canal se agota, todo el proceso se detiene, incluso si otros canales todavía tienen elementos.
Este es un patrón común donde tienes un único archivo de referencia que necesita reutilizarse en múltiples muestras. La solución es convertir el canal de referencia en un value channel que pueda reutilizarse indefinidamente.
Corregir el código¶
Hay un par de formas de abordar esto dependiendo de cuántos archivos se vean afectados.
Opción 1: Tienes un único archivo de referencia que reutilizas mucho. Puedes simplemente crear un tipo de value channel, que puede usarse una y otra vez. Hay tres formas de hacer esto:
1a Usar channel.value():
| exhausted.nf (fixed - Option 1a) | |
|---|---|
1b Usar el operador first():
| exhausted.nf (fixed - Option 1b) | |
|---|---|
1c. Usar el operador collect():
| exhausted.nf (fixed - Option 1c) | |
|---|---|
Opción 2: En escenarios más complejos, quizás donde tienes múltiples archivos de referencia para todas las muestras en el canal de muestras, puedes usar el operador combine para crear un nuevo canal que combine los dos canales en tuplas:
| exhausted.nf (fixed - Option 2) | |
|---|---|
El operador .combine() genera un producto cartesiano de los dos canales, por lo que cada elemento en reference_ch se emparejará con cada elemento en input_ch. Esto permite que el proceso se ejecute para cada muestra mientras sigue usando la referencia.
Esto requiere que se ajuste la entrada del proceso. En nuestro ejemplo, el inicio de la definición del proceso necesitaría ajustarse de la siguiente manera:
| exhausted.nf (fixed - Option 2) | |
|---|---|
Este enfoque puede no ser adecuado en todas las situaciones.
Ejecutar el pipeline¶
Prueba una de las correcciones anteriores y ejecuta el workflow nuevamente:
Salida del comando
Ahora deberías ver las tres muestras siendo procesadas en lugar de solo una.
2.3. Estructura de contenido de canal incorrecta¶
Cuando los workflows alcanzan cierto nivel de complejidad, puede ser un poco difícil hacer un seguimiento de las estructuras internas de cada canal, y es común generar discrepancias entre lo que el proceso espera y lo que el canal realmente contiene. Esto es más sutil que el problema que discutimos anteriormente, donde el número de canales era incorrecto. En este caso, puedes tener el número correcto de canales de entrada, pero la estructura interna de uno o más de esos canales no coincide con lo que espera el proceso.
Ejecutar el pipeline¶
Salida del comando
Launching `bad_channel_shape.nf` [hopeful_pare] DSL2 - revision: ffd66071a1
executor > local (3)
executor > local (3)
[3f/c2dcb3] PROCESS_FILES (3) [ 0%] 0 of 3 ✘
ERROR ~ Error executing process > 'PROCESS_FILES (1)'
Caused by:
Missing output file(s) `[sample1, file1.txt]_output.txt` expected by process `PROCESS_FILES (1)`
Command executed:
echo "Processing [sample1, file1.txt]" > [sample1, file1.txt]_output.txt
Command exit status:
0
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/d6/1fb69d1d93300bbc9d42f1875b981e
Tip: when you have fixed the problem you can continue the execution adding the option `-resume` to the run command line
-- Check '.nextflow.log' file for details
Revisar el código¶
Los corchetes en el mensaje de error proporcionan la pista aquí - el proceso está tratando la tupla como un valor único, que no es lo que queremos. Examinemos bad_channel_shape.nf:
Puedes ver que estamos generando un canal compuesto de tuplas: ['sample1', 'file1.txt'], pero el proceso espera un valor único, val sample_name. El comando ejecutado muestra que el proceso está intentando crear un archivo llamado [sample3, file3.txt]_output.txt, que no es la salida esperada.
Corregir el código¶
Para corregir esto, si el proceso requiere ambas entradas podríamos ajustar el proceso para aceptar una tupla:
| bad_channel_shape.nf | |
|---|---|
Ejecutar el pipeline¶
Elige una de las soluciones y vuelve a ejecutar el workflow:
Salida del comando
2.4. Técnicas de depuración de canales¶
Uso de .view() para inspección de canales¶
La herramienta de depuración más poderosa para los canales es el operador .view(). Con .view(), puedes entender la forma de tus canales en todas las etapas para ayudar con la depuración.
Ejecutar el pipeline¶
Ejecuta bad_channel_shape_viewed.nf para ver esto en acción:
Salida del comando
N E X T F L O W ~ version 25.10.2
Launching `bad_channel_shape_viewed.nf` [maniac_poisson] DSL2 - revision: b4f24dc9da
executor > local (3)
[c0/db76b3] PROCESS_FILES (3) [100%] 3 of 3 ✔
Channel content: [sample1, file1.txt]
Channel content: [sample2, file2.txt]
Channel content: [sample3, file3.txt]
After mapping: sample1
After mapping: sample2
After mapping: sample3
Revisar el código¶
Examinemos bad_channel_shape_viewed.nf para ver cómo se usa .view():
Corregir el código¶
Para evitar el uso excesivo de operaciones .view() en el futuro para entender el contenido del canal, es recomendable agregar algunos comentarios para ayudar:
| bad_channel_shape_viewed.nf (with comments) | |
|---|---|
Esto se volverá más importante a medida que tus workflows crezcan en complejidad y la estructura del canal se vuelva más opaca.
Ejecutar el pipeline¶
Salida del comando
N E X T F L O W ~ version 25.10.2
Launching `bad_channel_shape_viewed.nf` [marvelous_koch] DSL2 - revision: 03e79cdbad
executor > local (3)
[ff/d67cec] PROCESS_FILES (2) | 3 of 3 ✔
Channel content: [sample1, file1.txt]
Channel content: [sample2, file2.txt]
Channel content: [sample3, file3.txt]
After mapping: sample1
After mapping: sample2
After mapping: sample3
Conclusión¶
Muchos errores de estructura de canal pueden crearse con sintaxis Nextflow válida. Puedes depurar errores de estructura de canal entendiendo el flujo de datos, usando operadores .view() para inspección y reconociendo patrones de mensajes de error como corchetes que indican estructuras de tupla inesperadas.
¿Qué sigue?¶
Aprende sobre los errores creados por las definiciones de proceso.
3. Errores de Estructura de Proceso¶
La mayoría de los errores que encuentres relacionados con los procesos estarán relacionados con errores que hayas cometido al formar el comando, o con problemas relacionados con el software subyacente. Dicho esto, de manera similar a los problemas de canal anteriores, puedes cometer errores en la definición del proceso que no califican como errores de sintaxis, pero que causarán errores en tiempo de ejecución.
3.1. Archivos de salida faltantes¶
Un error común al escribir procesos es hacer algo que genera una discrepancia entre lo que el proceso espera y lo que se genera.
Ejecutar el pipeline¶
Salida del comando
N E X T F L O W ~ version 25.10.2
Launching `missing_output.nf` [zen_stone] DSL2 - revision: 37ff61f926
executor > local (3)
executor > local (3)
[fd/2642e9] process > PROCESS_FILES (2) [ 66%] 2 of 3, failed: 2
ERROR ~ Error executing process > 'PROCESS_FILES (3)'
Caused by:
Missing output file(s) `sample3.txt` expected by process `PROCESS_FILES (3)`
Command executed:
echo "Processing sample3" > sample3_output.txt
Command exit status:
0
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/02/9604d49fb8200a74d737c72a6c98ed
Tip: when you have fixed the problem you can continue the execution adding the option `-resume` to the run command line
-- Check '.nextflow.log' file for details
Revisar el código¶
El mensaje de error indica que el proceso esperaba producir un archivo de salida llamado sample3.txt, pero el script en realidad crea sample3_output.txt. Examinemos la definición del proceso en missing_output.nf:
| missing_output.nf | |
|---|---|
Deberías ver que hay una discrepancia entre el nombre del archivo de salida en el bloque output: y el que se usa en el script. Esta discrepancia hace que el proceso falle. Si encuentras este tipo de error, vuelve y verifica que las salidas coincidan entre la definición de tu proceso y tu bloque de salida.
Si el problema aún no está claro, revisa el directorio de trabajo para identificar los archivos de salida reales creados:
Para este ejemplo, esto nos indicaría que se está incorporando un sufijo _output en el nombre del archivo de salida, contrario a nuestra definición en output:.
Corregir el código¶
Corrige la discrepancia haciendo que el nombre del archivo de salida sea consistente:
Ejecutar el pipeline¶
Salida del comando
3.2. Software faltante¶
Otra clase de errores ocurre debido a errores en el aprovisionamiento de software. missing_software.nf es un workflow sintácticamente válido, pero depende de algún software externo para proporcionar el comando cowpy que usa.
Ejecutar el pipeline¶
Salida del comando
ERROR ~ Error executing process > 'PROCESS_FILES (3)'
Caused by:
Process `PROCESS_FILES (3)` terminated with an error exit status (127)
Command executed:
cowpy sample3 > sample3_output.txt
Command exit status:
127
Command output:
(empty)
Command error:
.command.sh: line 2: cowpy: command not found
Work dir:
/workspaces/training/side-quests/debugging/work/82/42a5bfb60c9c6ee63ebdbc2d51aa6e
Tip: you can try to figure out what's wrong by changing to the process work directory and showing the script file named `.command.sh`
-- Check '.nextflow.log' file for details
El proceso no tiene acceso al comando que estamos especificando. A veces esto se debe a que un script está presente en el directorio bin del workflow, pero no se ha hecho ejecutable. Otras veces es porque el software no está instalado en el contenedor o entorno donde se está ejecutando el workflow.
Revisar el código¶
Presta atención a ese código de salida 127 - te indica exactamente el problema. Examinemos missing_software.nf:
| missing_software.nf | |
|---|---|
Corregir el código¶
Hemos sido un poco engañosos aquí, y en realidad no hay nada malo con el código. Solo necesitamos especificar la configuración necesaria para ejecutar el proceso de tal manera que tenga acceso al comando en cuestión. En este caso el proceso tiene una definición de contenedor, por lo que todo lo que necesitamos hacer es ejecutar el workflow con Docker habilitado.
Ejecutar el pipeline¶
Hemos configurado un perfil Docker para ti en nextflow.config, por lo que puedes ejecutar el workflow con:
Salida del comando
Nota
Para aprender más sobre cómo Nextflow usa contenedores, consulta Hello Nextflow
3.3. Configuración de recursos incorrecta¶
En uso en producción, estarás configurando recursos en tus procesos. Por ejemplo, memory define la cantidad máxima de memoria disponible para tu proceso, y si el proceso la excede, tu planificador típicamente terminará el proceso y devolverá un código de salida de 137. No podemos demostrar eso aquí porque estamos usando el executor local, pero podemos mostrar algo similar con time.
Ejecutar el pipeline¶
bad_resources.nf tiene una configuración de proceso con un límite de tiempo poco realista de 1 milisegundo:
Salida del comando
N E X T F L O W ~ version 25.10.2
Launching `bad_resources.nf` [disturbed_elion] DSL2 - revision: 27d2066e86
executor > local (3)
[c0/ded8e1] PROCESS_FILES (3) | 0 of 3 ✘
ERROR ~ Error executing process > 'PROCESS_FILES (2)'
Caused by:
Process exceeded running time limit (1ms)
Command executed:
cowpy sample2 > sample2_output.txt
Command exit status:
-
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/53/f0a4cc56d6b3dc2a6754ff326f1349
Container:
community.wave.seqera.io/library/cowpy:1.1.5--3db457ae1977a273
Tip: you can replicate the issue by changing to the process work dir and entering the command `bash .command.run`
-- Check '.nextflow.log' file for details
Revisar el código¶
Examinemos bad_resources.nf:
| bad_resources.nf | |
|---|---|
Sabemos que el proceso tardará más de un segundo (hemos agregado un sleep para asegurarnos), pero el proceso está configurado para agotar el tiempo después de 1 milisegundo. ¡Alguien ha sido un poco poco realista con su configuración!
Corregir el código¶
Aumenta el límite de tiempo a un valor realista:
| bad_resources.nf | |
|---|---|
Ejecutar el pipeline¶
Salida del comando
Si te aseguras de leer tus mensajes de error, fallos como este no deberían desconcertarte por mucho tiempo. Pero asegúrate de entender los requisitos de recursos de los comandos que estás ejecutando para poder configurar tus directivas de recursos apropiadamente.
3.4. Técnicas de depuración de procesos¶
Cuando los procesos fallan o se comportan de manera inesperada, necesitas técnicas sistemáticas para investigar qué salió mal. El directorio de trabajo contiene toda la información que necesitas para depurar la ejecución del proceso.
Uso de la inspección del directorio de trabajo¶
La herramienta de depuración más poderosa para los procesos es examinar el directorio de trabajo. Cuando un proceso falla, Nextflow crea un directorio de trabajo para esa ejecución específica del proceso que contiene todos los archivos necesarios para entender qué sucedió.
Ejecutar el pipeline¶
Usemos el ejemplo missing_output.nf de antes para demostrar la inspección del directorio de trabajo (vuelve a generar una discrepancia en el nombre del archivo de salida si es necesario):
Salida del comando
N E X T F L O W ~ version 25.10.2
Launching `missing_output.nf` [irreverent_payne] DSL2 - revision: 3d5117f7e2
executor > local (3)
[5d/d544a4] PROCESS_FILES (2) | 0 of 3 ✘
ERROR ~ Error executing process > 'PROCESS_FILES (1)'
Caused by:
Missing output file(s) `sample1.txt` expected by process `PROCESS_FILES (1)`
Command executed:
echo "Processing sample1" > sample1_output.txt
Command exit status:
0
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/1e/2011154d0b0f001cd383d7364b5244
Tip: you can replicate the issue by changing to the process work dir and entering the command `bash .command.run`
-- Check '.nextflow.log' file for details
Revisar el directorio de trabajo¶
Cuando obtienes este error, el directorio de trabajo contiene toda la información de depuración. Encuentra la ruta del directorio de trabajo en el mensaje de error y examina su contenido:
# Encontrar el directorio de trabajo desde el mensaje de error
ls work/02/9604d49fb8200a74d737c72a6c98ed/
Luego puedes examinar los archivos clave:
Revisar el script del comando¶
El archivo .command.sh muestra exactamente qué comando se ejecutó:
Esto revela:
- Sustitución de variables: Si las variables de Nextflow se expandieron correctamente
- Rutas de archivos: Si los archivos de entrada se ubicaron correctamente
- Estructura del comando: Si la sintaxis del script es correcta
Problemas comunes a buscar:
- Comillas faltantes: Las variables que contienen espacios necesitan comillas apropiadas
- Rutas de archivos incorrectas: Archivos de entrada que no existen o están en ubicaciones incorrectas
- Nombres de variables incorrectos: Errores tipográficos en las referencias de variables
- Configuración de entorno faltante: Comandos que dependen de entornos específicos
Revisar la salida de error¶
El archivo .command.err contiene los mensajes de error reales:
Este archivo mostrará:
- Códigos de salida: 127 (comando no encontrado), 137 (terminado), etc.
- Errores de permisos: Problemas de acceso a archivos
- Errores de software: Mensajes de error específicos de la aplicación
- Errores de recursos: Memoria/tiempo límite excedido
Revisar la salida estándar¶
El archivo .command.out muestra lo que produjo tu comando:
Esto ayuda a verificar:
- Salida esperada: Si el comando produjo los resultados correctos
- Ejecución parcial: Si el comando comenzó pero falló a mitad de camino
- Información de depuración: Cualquier salida de diagnóstico de tu script
Revisar el código de salida¶
El archivo .exitcode contiene el código de salida del proceso:
Códigos de salida comunes y sus significados:
- Código de salida 127: Comando no encontrado - verifica la instalación del software
- Código de salida 137: Proceso terminado - verifica los límites de memoria/tiempo
Verificar la existencia de archivos¶
Cuando los procesos fallan debido a archivos de salida faltantes, verifica qué archivos se crearon realmente:
# Listar todos los archivos en el directorio de trabajo
ls -la work/02/9604d49fb8200a74d737c72a6c98ed/
Esto ayuda a identificar:
- Discrepancias en nombres de archivos: Archivos de salida con nombres diferentes a los esperados
- Problemas de permisos: Archivos que no se pudieron crear
- Problemas de ruta: Archivos creados en directorios incorrectos
En nuestro ejemplo anterior, esto nos confirmó que mientras nuestro sample3.txt esperado no estaba presente, sample3_output.txt sí lo estaba:
Conclusión¶
La depuración de procesos requiere examinar los directorios de trabajo para entender qué salió mal. Los archivos clave incluyen .command.sh (el script ejecutado), .command.err (mensajes de error) y .command.out (salida estándar). Los códigos de salida como 127 (comando no encontrado) y 137 (proceso terminado) proporcionan pistas de diagnóstico inmediatas sobre el tipo de fallo.
¿Qué sigue?¶
Aprende sobre las herramientas de depuración integradas de Nextflow y los enfoques sistemáticos para la resolución de problemas.
4. Herramientas de Depuración Integradas y Técnicas Avanzadas¶
Nextflow proporciona varias herramientas integradas poderosas para depurar y analizar la ejecución del workflow. Estas herramientas te ayudan a entender qué salió mal, dónde salió mal y cómo corregirlo eficientemente.
4.1. Salida de proceso en tiempo real¶
A veces necesitas ver qué está sucediendo dentro de los procesos en ejecución. Puedes habilitar la salida de proceso en tiempo real, que te muestra exactamente qué está haciendo cada tarea mientras se ejecuta.
Ejecutar el pipeline¶
bad_channel_shape_viewed.nf de nuestros ejemplos anteriores imprimió el contenido del canal usando .view(), pero también podemos usar la directiva debug para mostrar variables desde dentro del proceso mismo, lo cual demostramos en bad_channel_shape_viewed_debug.nf. Ejecuta el workflow:
Salida del comando
N E X T F L O W ~ version 25.10.2
Launching `bad_channel_shape_viewed_debug.nf` [agitated_crick] DSL2 - revision: ea3676d9ec
executor > local (3)
[c6/2dac51] process > PROCESS_FILES (3) [100%] 3 of 3 ✔
Channel content: [sample1, file1.txt]
Channel content: [sample2, file2.txt]
Channel content: [sample3, file3.txt]
After mapping: sample1
After mapping: sample2
After mapping: sample3
Sample name inside process is sample2
Sample name inside process is sample1
Sample name inside process is sample3
Revisar el código¶
Examinemos bad_channel_shape_viewed_debug.nf para ver cómo funciona la directiva debug:
| bad_channel_shape_viewed_debug.nf | |
|---|---|
La directiva debug puede ser una forma rápida y conveniente de entender el entorno de un proceso.
4.2. Modo de vista previa¶
A veces quieres detectar problemas antes de que se ejecuten los procesos. Nextflow proporciona un indicador para este tipo de depuración proactiva: -preview.
Ejecutar el pipeline¶
El modo de vista previa te permite probar la lógica del workflow sin ejecutar comandos. Esto puede ser bastante útil para verificar rápidamente la estructura de tu workflow y asegurarte de que los procesos estén conectados correctamente sin ejecutar ningún comando real.
Nota
Si corregiste bad_syntax.nf anteriormente, vuelve a introducir el error de sintaxis eliminando la llave de cierre después del bloque de script antes de ejecutar este comando.
Ejecuta este comando:
Salida del comando
El modo de vista previa es particularmente útil para detectar errores de sintaxis temprano sin ejecutar ningún proceso. Valida la estructura del workflow y las conexiones de los procesos antes de la ejecución.
4.3. Ejecución stub para pruebas de lógica¶
A veces los errores son difíciles de depurar porque los comandos tardan demasiado, requieren software especial o fallan por razones complejas. La ejecución stub te permite probar la lógica del workflow sin ejecutar los comandos reales.
Ejecutar el pipeline¶
Cuando estás desarrollando un proceso de Nextflow, puedes usar la directiva stub para definir comandos 'ficticios' que generan salidas de la forma correcta sin ejecutar el comando real. Este enfoque es particularmente valioso cuando quieres verificar que la lógica de tu workflow es correcta antes de lidiar con las complejidades del software real.
Por ejemplo, ¿recuerdas nuestro missing_software.nf de antes? ¿El que tenía software faltante que impedía que el workflow se ejecutara hasta que agregamos -profile docker? missing_software_with_stub.nf es un workflow muy similar. Si lo ejecutamos de la misma manera, generaremos el mismo error:
Salida del comando
ERROR ~ Error executing process > 'PROCESS_FILES (3)'
Caused by:
Process `PROCESS_FILES (3)` terminated with an error exit status (127)
Command executed:
cowpy sample3 > sample3_output.txt
Command exit status:
127
Command output:
(empty)
Command error:
.command.sh: line 2: cowpy: command not found
Work dir:
/workspaces/training/side-quests/debugging/work/82/42a5bfb60c9c6ee63ebdbc2d51aa6e
Tip: you can try to figure out what's wrong by changing to the process work directory and showing the script file named `.command.sh`
-- Check '.nextflow.log' file for details
Sin embargo, este workflow no producirá errores si lo ejecutamos con -stub-run, incluso sin el perfil docker:
Salida del comando
Revisar el código¶
Examinemos missing_software_with_stub.nf:
| missing_software.nf (with stub) | |
|---|---|
En comparación con missing_software.nf, este proceso tiene una directiva stub: que especifica un comando a usar en lugar del especificado en script:, en caso de que Nextflow se ejecute en modo stub.
El comando touch que estamos usando aquí no depende de ningún software o entradas apropiadas, y se ejecutará en todas las situaciones, permitiéndonos depurar la lógica del workflow sin preocuparnos por los aspectos internos del proceso.
La ejecución stub ayuda a depurar:
- Estructura del canal y flujo de datos
- Conexiones y dependencias de procesos
- Propagación de parámetros
- Lógica del workflow sin dependencias de software
4.4. Enfoque sistemático de depuración¶
Ahora que has aprendido técnicas de depuración individuales - desde archivos de traza y directorios de trabajo hasta el modo de vista previa, la ejecución stub y el monitoreo de recursos - vamos a unirlas en una metodología sistemática. Tener un enfoque estructurado evita que te abrumes con errores complejos y asegura que no pierdas pistas importantes.
Esta metodología combina todas las herramientas que hemos cubierto en un workflow eficiente:
Método de depuración de cuatro fases:
Fase 1: Resolución de errores de sintaxis (5 minutos)
- Busca subrayados rojos en VSCode o tu IDE
- Ejecuta
nextflow run workflow.nf -previewpara identificar problemas de sintaxis - Corrige todos los errores de sintaxis (llaves faltantes, comas al final, etc.)
- Asegúrate de que el workflow se analice correctamente antes de continuar
Fase 2: Evaluación rápida (5 minutos)
- Lee los mensajes de error de ejecución cuidadosamente
- Verifica si es un error de ejecución, lógica o recursos
- Usa el modo de vista previa para probar la lógica básica del workflow
Fase 3: Investigación detallada (15-30 minutos)
- Encuentra el directorio de trabajo de la tarea fallida
- Examina los archivos de registro
- Agrega operadores
.view()para inspeccionar los canales - Usa
-stub-runpara probar la lógica del workflow sin ejecución
Fase 4: Corrección y validación (15 minutos)
- Realiza correcciones mínimas y específicas
- Prueba con resume:
nextflow run workflow.nf -resume - Verifica la ejecución completa del workflow
Uso de resume para una depuración eficiente
Una vez que hayas identificado un problema, necesitas una forma eficiente de probar tus correcciones sin perder tiempo volviendo a ejecutar las partes exitosas de tu workflow. La funcionalidad -resume de Nextflow es invaluable para la depuración.
Habrás encontrado -resume si has trabajado en Hello Nextflow, y es importante que lo uses bien al depurar para ahorrarte tiempo de espera mientras los procesos anteriores a tu proceso problemático se ejecutan.
Estrategia de depuración con resume:
- Ejecuta el workflow hasta el fallo
- Examina el directorio de trabajo de la tarea fallida
- Corrige el problema específico
- Reanuda para probar solo la corrección
- Repite hasta que el workflow se complete
Perfil de configuración de depuración¶
Para hacer este enfoque sistemático aún más eficiente, puedes crear una configuración de depuración dedicada que habilite automáticamente todas las herramientas que necesitas:
| nextflow.config (debug profile) | |
|---|---|
Luego puedes ejecutar el pipeline con este perfil habilitado:
Este perfil habilita la salida en tiempo real, preserva los directorios de trabajo y limita la paralelización para una depuración más fácil.
4.5. Ejercicio práctico de depuración¶
Ahora es el momento de poner en práctica el enfoque sistemático de depuración. El workflow buggy_workflow.nf contiene varios errores comunes que representan los tipos de problemas que encontrarás en el desarrollo del mundo real.
Ejercicio
Usa el enfoque sistemático de depuración para identificar y corregir todos los errores en buggy_workflow.nf. Este workflow intenta procesar datos de muestras desde un archivo CSV pero contiene múltiples errores intencionales que representan escenarios comunes de depuración.
Comienza ejecutando el workflow para ver el primer error:
Salida del comando
N E X T F L O W ~ version 25.10.2
Launching `buggy_workflow.nf` [wise_ramanujan] DSL2 - revision: d51a8e83fd
ERROR ~ Range [11, 12) out of bounds for length 11
-- Check '.nextflow.log' file for details
Este error críptico indica un problema de análisis alrededor de las líneas 11-12 en el bloque params{}. El analizador v2 detecta problemas estructurales temprano.
Aplica el método de depuración de cuatro fases que has aprendido:
Fase 1: Resolución de errores de sintaxis
- Busca subrayados rojos en VSCode o tu IDE
- Ejecuta nextflow run workflow.nf -preview para identificar problemas de sintaxis
- Corrige todos los errores de sintaxis (llaves faltantes, comas al final, etc.)
- Asegúrate de que el workflow se analice correctamente antes de continuar
Fase 2: Evaluación rápida
- Lee los mensajes de error de ejecución cuidadosamente
- Identifica si los errores son de ejecución, lógica o recursos
- Usa el modo -preview para probar la lógica básica del workflow
Fase 3: Investigación detallada
- Examina los directorios de trabajo de las tareas fallidas
- Agrega operadores .view() para inspeccionar los canales
- Revisa los archivos de registro en los directorios de trabajo
- Usa -stub-run para probar la lógica del workflow sin ejecución
Fase 4: Corrección y validación
- Realiza correcciones específicas
- Usa -resume para probar las correcciones eficientemente
- Verifica la ejecución completa del workflow
Herramientas de depuración a tu disposición:
# Modo de vista previa para verificación de sintaxis
nextflow run buggy_workflow.nf -preview
# Perfil de depuración para salida detallada
nextflow run buggy_workflow.nf -profile debug
# Ejecución stub para pruebas de lógica
nextflow run buggy_workflow.nf -stub-run
# Reanudar después de las correcciones
nextflow run buggy_workflow.nf -resume
Solución
El buggy_workflow.nf contiene 9 o 10 errores distintos (dependiendo de cómo los cuentes) que cubren todas las categorías principales de depuración. Aquí hay un desglose sistemático de cada error y cómo corregirlo.
Comencemos con esos errores de sintaxis:
Error 1: Error de sintaxis - Coma al final
Corrección: Elimina la coma al finalError 2: Error de sintaxis - Llave de cierre faltante
Error 3: Error de nombre de variable
Error 4: Error de variable no definida
En este punto el workflow se ejecutará, pero seguiremos obteniendo errores (por ejemplo, Path value cannot be null en processFiles), causados por una estructura de canal incorrecta.
Error 5: Error de estructura de canal - Salida de map incorrecta
Pero esto romperá nuestra corrección para ejecutar heavyProcess() arriba, por lo que necesitaremos usar un map para pasar solo los IDs de muestra a ese proceso:
Error 6: Estructura de canal incorrecta para heavyProcess
Ahora avanzamos un poco más pero recibimos un error sobre No such variable: i, porque no escapamos una variable Bash.
Error 7: Error de escape de variable Bash
Ahora obtenemos Process exceeded running time limit (1ms), por lo que corregimos el límite de tiempo de ejecución para el proceso relevante:
Error 8: Error de configuración de recursos
A continuación tenemos un error de Missing output file(s) que resolver:
Error 9: Discrepancia en el nombre del archivo de salida
Los primeros dos procesos se ejecutaron, pero no el tercero.
Error 10: Discrepancia en el nombre del archivo de salida
Con eso, el workflow completo debería ejecutarse.
Workflow corregido completo:
Categorías de errores cubiertas:
- Errores de sintaxis: Llaves faltantes, comas al final, variables no definidas
- Errores de estructura de canal: Formas de datos incorrectas, canales no definidos
- Errores de proceso: Discrepancias en nombres de archivos de salida, escape de variables
- Errores de recursos: Límites de tiempo poco realistas
Lecciones clave de depuración:
- Lee los mensajes de error cuidadosamente - a menudo apuntan directamente al problema
- Usa enfoques sistemáticos - corrige un error a la vez y prueba con
-resume - Entiende el flujo de datos - los errores de estructura de canal son a menudo los más sutiles
- Revisa los directorios de trabajo - cuando los procesos fallan, los registros te dicen exactamente qué salió mal
Resumen¶
En esta misión secundaria, has aprendido un conjunto de técnicas sistemáticas para depurar workflows de Nextflow. Aplicar estas técnicas en tu propio trabajo te permitirá pasar menos tiempo luchando con tu computadora, resolver problemas más rápido y protegerte de problemas futuros.
Patrones clave¶
1. Cómo identificar y corregir errores de sintaxis:
- Interpretar los mensajes de error de Nextflow y localizar problemas
- Errores de sintaxis comunes: llaves faltantes, palabras clave incorrectas, variables no definidas
- Distinguir entre variables de Nextflow (Groovy) y Bash
- Usar las funciones de la extensión de VS Code para la detección temprana de errores
// Llave faltante - busca subrayados rojos en el IDE
process FOO {
script:
"""
echo "hello"
"""
// } <-- ¡faltante!
// Palabra clave incorrecta
inputs: // Debería ser 'input:'
// Variable no definida - escapa con barra invertida para variables Bash
echo "${undefined_var}" // Variable Nextflow (error si no está definida)
echo "\${bash_var}" // Variable Bash (escapada)
2. Cómo depurar problemas de estructura de canal:
- Entender la cardinalidad del canal y los problemas de agotamiento
- Depurar discrepancias en la estructura del contenido del canal
- Usar operadores
.view()para inspección del canal - Reconocer patrones de error como corchetes en la salida
// Inspeccionar el contenido del canal
my_channel.view { "Content: $it" }
// Convertir queue channel a value channel (previene el agotamiento)
reference_ch = channel.value('ref.fa')
// o
reference_ch = channel.of('ref.fa').first()
3. Cómo solucionar problemas de ejecución de procesos:
- Diagnosticar errores de archivos de salida faltantes
- Entender los códigos de salida (127 para software faltante, 137 para problemas de memoria)
- Investigar directorios de trabajo y archivos de comandos
- Configurar los recursos apropiadamente
# Verificar qué se ejecutó realmente
cat work/ab/cdef12/.command.sh
# Verificar la salida de error
cat work/ab/cdef12/.command.err
# Código de salida 127 = comando no encontrado
# Código de salida 137 = terminado (límite de memoria/tiempo)
4. Cómo usar las herramientas de depuración integradas de Nextflow:
- Aprovechar el modo de vista previa y la depuración en tiempo real
- Implementar la ejecución stub para pruebas de lógica
- Aplicar resume para ciclos de depuración eficientes
- Seguir una metodología sistemática de depuración de cuatro fases
Referencia rápida de depuración
¿Errores de sintaxis? → Revisa las advertencias de VSCode, ejecuta nextflow run workflow.nf -preview
¿Problemas de canal? → Usa .view() para inspeccionar el contenido: my_channel.view()
¿Fallos de proceso? → Revisa los archivos del directorio de trabajo:
.command.sh- el script ejecutado.command.err- mensajes de error.exitcode- estado de salida (127 = comando no encontrado, 137 = terminado)
¿Comportamiento misterioso? → Ejecuta con -stub-run para probar la lógica del workflow
¿Realizaste correcciones? → Usa -resume para ahorrar tiempo en las pruebas: nextflow run workflow.nf -resume
Recursos adicionales¶
- Guía de resolución de problemas de Nextflow: Documentación oficial de resolución de problemas
- Entendiendo los canales de Nextflow: Análisis profundo de los tipos de canal y su comportamiento
- Referencia de directivas de proceso: Todas las opciones de configuración de proceso disponibles
- nf-test: Marco de pruebas para pipelines de Nextflow
- Comunidad de Nextflow en Slack: Obtén ayuda de la comunidad
Para workflows en producción, considera:
- Configurar Seqera Platform para monitoreo y depuración a escala
- Usar contenedores Wave para entornos de software reproducibles
Recuerda: La depuración efectiva es una habilidad que mejora con la práctica. La metodología sistemática y el conjunto completo de herramientas que has adquirido aquí te servirán bien a lo largo de tu trayectoria de desarrollo con Nextflow.
¿Qué sigue?¶
Regresa al menú de misiones secundarias o haz clic en el botón en la parte inferior derecha de la página para pasar al siguiente tema de la lista.