Parte 2: Reescribir Hello para nf-core¶
Traducción asistida por IA - más información y sugerencias
En esta segunda parte del curso de entrenamiento Hello nf-core, te mostramos cómo crear una versión compatible con nf-core del pipeline producido por el curso para principiantes Hello Nextflow.
Vamos a hacer esto en dos fases: primero, usaremos las herramientas nf-core para crear una estructura base de pipeline, y luego injertaremos el código del pipeline 'regular' existente sobre esa estructura.
Si no estás familiarizado con el pipeline Hello o necesitas un recordatorio, consulta esta página de información.
Consejo
Esta parte del curso presentará dos mecanismos importantes de Nextflow que no se cubren en el curso introductorio Hello Nextflow: meta maps y workflows of workflows, ambos cubiertos en detalle en los Side Quests enlazados.
Las instrucciones a continuación incluyen la información esencial que necesitas para entender cómo se usan en el contexto de nf-core, pero puede ser mucho para asimilar de una vez. Si tienes tiempo, te recomendamos trabajar primero en los dos Side Quests (en cualquier orden):
Nota
Asegúrate de estar en el directorio hello-nf-core en tu terminal.
1. Examinar la estructura del código del pipeline¶
El proyecto nf-core aplica directrices estrictas sobre cómo se estructuran los pipelines, y cómo se organiza, configura y documenta el código.
Antes de abordar nuestro proyecto de creación de pipeline, necesitamos entender esa estructura y organización.
Así que veamos cómo está organizado el código del pipeline en el repositorio nf-core/demo, usando el enlace simbólico pipelines que creamos en la Parte 1.
Como recordatorio, puedes usar tree o el explorador de archivos para encontrar y abrir el directorio nf-core/demo.
Contenido del directorio
pipelines/nf-core/demo
├── assets
├── CHANGELOG.md
├── CITATIONS.md
├── CODE_OF_CONDUCT.md
├── conf
├── docs
├── LICENSE
├── main.nf
├── modules
├── modules.json
├── nextflow.config
├── nextflow_schema.json
├── nf-test.config
├── README.md
├── ro-crate-metadata.json
├── subworkflows
├── tests
├── tower.yml
└── workflows
Por ahora nos vamos a enfocar específicamente en los componentes del código del pipeline (main.nf, workflows, subworkflows, modules) y cómo se relacionan entre sí.
1.1. Estructura modular de los workflows nf-core¶
La organización estándar del código de un pipeline nf-core sigue una estructura modular diseñada para maximizar la reutilización del código, como se introdujo en Hello Modules, Parte 4 del curso Hello Nextflow, aunque en el estilo típico de nf-core, esto se implementa con un poco de complejidad adicional. Específicamente, los pipelines nf-core hacen un uso abundante de subworkflows, es decir, scripts de workflow que son importados por un workflow padre.
Eso puede sonar un poco abstracto, así que veamos cómo se usa en la práctica en el pipeline nf-core/demo.
Si miras dentro del archivo main.nf, verás que importa un workflow llamado DEMO desde workflows/demo.nf, así como algunos módulos y subworkflows.
Así es como se ven las relaciones entre los componentes de código relevantes:
El workflow sin nombre en main.nf se llama script de punto de entrada. Actúa como un envoltorio para dos tipos de workflows anidados: el workflow DEMO que contiene la lógica de análisis real, ubicado en workflows/demo.nf, y un conjunto de workflows de mantenimiento ubicados bajo subworkflows/.
El workflow demo.nf llama a módulos ubicados bajo modules/; estos contienen los procesos que realizarán los pasos de análisis reales.
Nota
Los subworkflows no se limitan a funciones de mantenimiento, y pueden hacer uso de módulos de procesos.
El pipeline nf-core/demo que se muestra aquí resulta ser de los más simples en el espectro, pero otros pipelines nf-core (como nf-core/rnaseq) utilizan subworkflows que participan en el análisis real.
Ahora revisemos estos componentes en detalle.
1.2. El script de punto de entrada: main.nf¶
El script main.nf es el punto de entrada desde el que Nextflow comienza cuando ejecutamos nextflow run nf-core/demo.
Esto significa que cuando ejecutas nextflow run nf-core/demo para correr el pipeline, Nextflow encuentra y ejecuta automáticamente el script main.nf.
Esto funciona para cualquier pipeline de Nextflow que siga esta convención de nomenclatura y estructura, no solo los pipelines nf-core.
Usar un script de punto de entrada facilita la ejecución de subworkflows de 'mantenimiento' estandarizados antes y después de que se ejecute el script de análisis real. Revisaremos esos después de haber examinado el workflow de análisis real y sus módulos.
1.3. El script de análisis: workflows/demo.nf¶
El workflow workflows/demo.nf es donde se almacena la lógica central del pipeline.
Está estructurado de manera similar a un workflow normal de Nextflow, excepto que está diseñado para ser llamado desde un workflow padre, lo que requiere algunas características adicionales.
Cubriremos las diferencias relevantes en la siguiente parte de este curso, cuando abordemos la conversión del pipeline Hello simple de Hello Nextflow a una forma compatible con nf-core.
El workflow demo.nf llama a módulos ubicados bajo modules/, que revisaremos a continuación.
Nota
Algunos workflows de análisis nf-core muestran niveles adicionales de anidamiento al llamar a subworkflows de nivel inferior. Esto se usa principalmente para envolver dos o más módulos que se usan comúnmente juntos en segmentos de pipeline fácilmente reutilizables. Puedes ver algunos ejemplos navegando por los subworkflows nf-core disponibles en el sitio web de nf-core.
Cuando el script de análisis usa subworkflows, estos se almacenan bajo el directorio subworkflows/.
1.4. Los módulos¶
Los módulos son donde vive el código de los procesos, como se describe en la Parte 4 del curso de entrenamiento Hello Nextflow.
En el proyecto nf-core, los módulos se organizan usando una estructura anidada de múltiples niveles que refleja tanto su origen como su contenido.
En el nivel superior, los módulos se diferencian como nf-core o local (no parte del proyecto nf-core), y luego se colocan en un directorio con el nombre de la(s) herramienta(s) que envuelven.
Si la herramienta pertenece a un toolkit (es decir, un paquete que contiene múltiples herramientas), entonces hay un nivel de directorio intermedio con el nombre del toolkit.
Puedes ver esto aplicado en la práctica a los módulos del pipeline nf-core/demo:
Contenido del directorio
Aquí puedes ver que los módulos fastqc y multiqc están en el nivel superior dentro de los módulos nf-core, mientras que el módulo trim está bajo el toolkit al que pertenece, seqtk.
En este caso no hay módulos local.
El archivo de código del módulo que describe el proceso siempre se llama main.nf, y va acompañado de pruebas y archivos .yml que ignoraremos por ahora.
En conjunto, el workflow de punto de entrada, el workflow de análisis y los módulos son suficientes para ejecutar las partes 'interesantes' del pipeline. Sin embargo, sabemos que también hay subworkflows de mantenimiento, así que veámoslos ahora.
1.5. Los subworkflows de mantenimiento¶
Al igual que los módulos, los subworkflows se diferencian en directorios local y nf-core, y cada subworkflow tiene su propia estructura de directorio anidada con su propio script main.nf, pruebas y archivo .yml.
Contenido del directorio
pipelines/nf-core/demo/subworkflows
├── local
│ └── utils_nfcore_demo_pipeline
│ └── main.nf
└── nf-core
├── utils_nextflow_pipeline
│ ├── main.nf
│ ├── meta.yml
│ └── tests
├── utils_nfcore_pipeline
│ ├── main.nf
│ ├── meta.yml
│ └── tests
└── utils_nfschema_plugin
├── main.nf
├── meta.yml
└── tests
9 directories, 7 files
Como se señaló anteriormente, el pipeline nf-core/demo no incluye ningún subworkflow específico de análisis, por lo que todos los subworkflows que vemos aquí son los llamados workflows de 'mantenimiento' o 'utilidad', como lo indica el prefijo utils_ en sus nombres.
Estos subworkflows son los que producen el encabezado nf-core en la salida de consola, entre otras funciones accesorias.
Consejo
Además de su patrón de nomenclatura, otra indicación de que estos subworkflows no realizan ninguna función verdaderamente relacionada con el análisis es que no llaman a ningún proceso en absoluto.
Esto completa el resumen de los componentes de código principales que constituyen el pipeline nf-core/demo.
Conclusión¶
Ahora tienes una comprensión de alto nivel de la estructura modular de los pipelines nf-core.
¿Qué sigue?¶
Crear una estructura base de pipeline usando las herramientas nf-core.
2. Crear un nuevo proyecto de pipeline¶
Como has visto, los pipelines nf-core siguen una estructura estandarizada con muchos archivos accesorios. Crear todo eso desde cero sería muy tedioso, por lo que la comunidad nf-core ha desarrollado herramientas para hacerlo desde una plantilla, facilitando el proceso inicial.
2.1. Ejecutar la herramienta de creación de pipeline basada en plantilla¶
Comencemos creando un nuevo pipeline con el comando nf-core pipelines create.
Esto creará una nueva estructura base de pipeline usando la plantilla base de nf-core, personalizada con un nombre de pipeline, descripción y autor.
Ejecutar este comando abrirá una Interfaz de Usuario de Texto (TUI) para la creación del pipeline:
Esta TUI te pedirá que proporciones información básica sobre tu pipeline y te ofrecerá opciones de funcionalidades para incluir o excluir en tu estructura base.
- En la pantalla de bienvenida, haz clic en Let's go!.
- En la pantalla
Choose pipeline type, haz clic en Custom. - Ingresa los detalles de tu pipeline como se indica a continuación (reemplazando
< TU NOMBRE >con tu propio nombre), luego haz clic en Next.
[ ] GitHub organisation: core
[ ] Workflow name: hello
[ ] A short description of your pipeline: A basic nf-core style version of Hello Nextflow
[ ] Name of the main author(s): < YOUR NAME >
- En la pantalla Template features, establece
Toggle all featuresen off, luego habilita selectivamente las siguientes opciones. Verifica tus selecciones y haz clic en Continue.
[ ] Add testing profiles
[ ] Use nf-core components
[ ] Use nf-schema
[ ] Add configuration files
[ ] Add documentation
- En la pantalla
Final details, haz clic en Finish. Espera a que se cree el pipeline, luego haz clic en Continue. - En la pantalla Create GitHub repository, haz clic en Finish without creating a repo. Esto mostrará instrucciones para crear un repositorio de GitHub más adelante. Ignóralas y haz clic en Close.
Una vez que la TUI se cierre, deberías ver la siguiente salida en la consola.
Salida del comando
No hay una confirmación explícita en la salida de consola de que la creación del pipeline funcionó, pero deberías ver un nuevo directorio llamado core-hello.
Visualiza el contenido del nuevo directorio para ver cuánto trabajo te ahorraste usando la plantilla.
Contenido del directorio
core-hello/
├── README.md
├── assets
│ ├── samplesheet.csv
│ └── schema_input.json
├── conf
│ ├── base.config
│ ├── modules.config
│ ├── test.config
│ └── test_full.config
├── docs
│ ├── README.md
│ ├── output.md
│ └── usage.md
├── main.nf
├── modules.json
├── nextflow.config
├── nextflow_schema.json
├── subworkflows
│ ├── local
│ │ └── utils_nfcore_hello_pipeline
│ │ └── main.nf
│ └── nf-core
│ ├── utils_nextflow_pipeline
│ │ ├── main.nf
│ │ ├── meta.yml
│ │ └── tests
│ │ ├── main.function.nf.test
│ │ ├── main.function.nf.test.snap
│ │ ├── main.workflow.nf.test
│ │ └── nextflow.config
│ ├── utils_nfcore_pipeline
│ │ ├── main.nf
│ │ ├── meta.yml
│ │ └── tests
│ │ ├── main.function.nf.test
│ │ ├── main.function.nf.test.snap
│ │ ├── main.workflow.nf.test
│ │ ├── main.workflow.nf.test.snap
│ │ └── nextflow.config
│ └── utils_nfschema_plugin
│ ├── main.nf
│ ├── meta.yml
│ └── tests
│ ├── main.nf.test
│ ├── nextflow.config
│ └── nextflow_schema.json
└── workflows
└── hello.nf
15 directories, 34 files
¡Son muchos archivos! No te preocupes si todavía te sientes un poco perdido; recorreremos las partes importantes en breve, y luego paso a paso a lo largo del resto del curso.
En general, esto debería verse similar a la estructura de código que observamos para el pipeline nf-core/demo, excepto que aquí no hay un directorio modules.
2.2. Probar que la estructura base es funcional¶
Lo creas o no, aunque aún no has agregado módulos para que haga trabajo real, la estructura base del pipeline puede ejecutarse usando el perfil de prueba, de la misma manera que ejecutamos el pipeline nf-core/demo.
Salida del comando
N E X T F L O W ~ version 25.10.4
Launching `./core-hello/main.nf` [scruffy_marconi] DSL2 - revision: b9e9b3b8de
Downloading plugin nf-schema@2.5.1
Input/output options
input : https://raw.githubusercontent.com/nf-core/test-datasets/viralrecon/samplesheet/samplesheet_test_illumina_amplicon.csv
outdir : core-hello-results
Institutional config options
config_profile_name : Test profile
config_profile_description: Minimal test dataset to check pipeline function
Generic options
trace_report_suffix : 2025-11-21_04-47-18
Core Nextflow options
runName : scruffy_marconi
containerEngine : docker
launchDir : /workspaces/training/hello-nf-core
workDir : /workspaces/training/hello-nf-core/work
projectDir : /workspaces/training/hello-nf-core/core-hello
userName : root
profile : docker,test
configFiles : /workspaces/training/hello-nf-core/core-hello/nextflow.config
!! Only displaying parameters that differ from the pipeline defaults !!
------------------------------------------------------
-[core/hello] Pipeline completed successfully-
Esto te muestra que toda la estructura básica está en su lugar. Entonces, ¿dónde están las salidas? ¿Hay alguna?
De hecho, se creó un nuevo directorio de resultados llamado core-hello-results que contiene los reportes de ejecución estándar:
Contenido del directorio
core-hello-results
└── pipeline_info
├── execution_report_2025-11-21_04-47-18.html
├── execution_timeline_2025-11-21_04-47-18.html
├── execution_trace_2025-11-21_04-47-18.txt
├── hello_software_versions.yml
├── params_2025-11-21_04-47-18.json
└── pipeline_dag_2025-11-21_04-47-18.html
1 directory, 6 files
Puedes echar un vistazo a los reportes para ver qué se ejecutó, y la respuesta es: ¡nada en absoluto!

Echemos un vistazo más de cerca a lo que realmente hay en el código.
2.3. Examinar la estructura de la estructura base¶
Si recuerdas la estructura del pipeline nf-core/demo, había un archivo main.nf que contenía un workflow de punto de entrada que envolvía el workflow DEMO.
Ahora si abres el archivo main.nf en tu proyecto recién creado, verás que importa un workflow llamado HELLO desde workflows/hello.nf.
Ese es el equivalente directo al workflow DEMO, aunque por el momento es solo un placeholder.
Y en consecuencia, así es como se ve la estructura general de la estructura base del pipeline:
¡Esto debería recordarte la estructura del pipeline nf-core/demo!
La única diferencia real es que el workflow DEMO incluía procesos de módulos.
Aquí, el workflow HELLO equivalente aún no incluye ningún proceso.
Veamos más de cerca.
2.4. Examinar el workflow placeholder¶
Este sirve como placeholder para nuestro workflow de análisis, con algo de funcionalidad nf-core ya en su lugar.
Comparado con un workflow básico de Nextflow como el desarrollado en Hello Nextflow, notarás algunas cosas que son nuevas aquí (líneas destacadas arriba):
- El bloque workflow tiene un nombre
- Las entradas del workflow se declaran usando la palabra clave
take:y la construcción del canal se mueve al workflow padre - El contenido del workflow se coloca dentro de un bloque
main: - Las salidas se declaran usando la palabra clave
emit:
Estas son características opcionales de Nextflow que hacen que el workflow sea componible, lo que significa que puede ser llamado desde dentro de otro workflow.
El bloque Channel.topic
Puede que hayas notado el bloque def topic_versions = Channel.topic("versions") que comienza en la línea 17.
Este es código de mantenimiento estándar que recopila información de versiones de software de todos los módulos automáticamente.
nf-core está implementando este mecanismo en todos los pipelines en 2026, por lo que lo verás en todos los nuevos pipelines a partir de ahora.
La Parte 4 de este curso explica cómo funciona en detalle.
Vamos a necesitar conectar la lógica relevante de nuestro workflow de interés en esa estructura.
Conclusión¶
Ahora sabes cómo crear una estructura base de pipeline usando las herramientas nf-core y compararla con la estructura del pipeline demo.
¿Qué sigue?¶
Aprende cómo hacer que un workflow simple sea componible como preludio para hacerlo compatible con nf-core.
3. Hacer el workflow Hello Nextflow componible¶
Ahora es momento de trabajar integrando nuestro workflow en la estructura base nf-core.
Como recordatorio, estamos trabajando con el workflow presentado en nuestro curso de entrenamiento Hello Nextflow. Ese workflow fue escrito como un workflow simple sin nombre que puede ejecutarse por sí solo.
Para mapear claramente qué partes del workflow original deben ir a dónde en la estructura base nf-core, vamos a comenzar transformando el workflow Hello original en un workflow componible que pueda ejecutarse desde dentro de un workflow padre, como requiere la plantilla nf-core.
Esto es lo que estamos tratando de construir ahora mismo:
Efectivamente, queremos imitar la estructura modular de la estructura base nf-core, pero con menos complejidad para empezar.
Te proporcionamos una copia limpia y completamente funcional del workflow Hello Nextflow completado en el directorio original-hello junto con sus módulos y el archivo CSV predeterminado que espera usar como entrada.
Contenido del directorio
Siéntete libre de ejecutarlo para verificar que funciona:
Salida del comando
Si eso funciona, estás listo para comenzar.
3.1. Modificar el workflow Hello original¶
Abramos el archivo de workflow hello.nf para inspeccionar el código, que se muestra completo a continuación (sin contar los procesos, que están en módulos):
Como puedes ver, este workflow fue escrito como un workflow simple sin nombre que puede ejecutarse por sí solo. Para hacerlo componible, vamos a realizar los siguientes cambios:
- Nombrar el workflow
- Reemplazar la construcción del canal con
take: - Anteponer las operaciones del workflow con
main: - Agregar la declaración
emit:
Recorramos los cambios necesarios uno por uno.
3.1.1. Nombrar el workflow¶
Primero, démosle un nombre al workflow para poder referirnos a él desde un workflow padre.
Las mismas convenciones se aplican a los nombres de workflow que a los nombres de módulos.
3.1.2. Reemplazar la construcción de canal con take¶
Ahora, reemplaza la construcción del canal con una simple declaración take que declare las entradas esperadas.
Esto deja los detalles de cómo se proporcionan las entradas al workflow padre.
Ya que estamos en eso, también podemos comentar la línea params.greeting = 'greetings.csv'
Nota
Si tienes instalada la extensión del servidor de lenguaje Nextflow, el verificador de sintaxis iluminará tu código con garabatos rojos.
Eso es porque si pones una declaración take:, también debes tener un main:.
Agregaremos eso en el siguiente paso.
3.1.3. Anteponer las operaciones del workflow con la declaración main¶
A continuación, agrega una declaración main antes del resto de las operaciones llamadas en el cuerpo del workflow.
Esto básicamente dice 'esto es lo que este workflow hace'.
3.1.4. Agregar declaración emit¶
Finalmente, agrega una declaración emit que declare cuáles son las salidas finales del workflow.
Esta es una adición completamente nueva al código comparado con el workflow original.
3.1.5. Resumen de los cambios completados¶
Si has hecho todos los cambios como se describe, tu workflow ahora debería verse así:
Esto describe todo lo que Nextflow necesita EXCEPTO qué alimentar en el canal de entrada. Eso se va a definir en el workflow padre, también llamado workflow de punto de entrada.
3.2. Hacer un workflow de punto de entrada ficticio¶
Antes de integrar nuestro workflow componible en la compleja estructura base nf-core, verifiquemos que funcione correctamente. Podemos hacer un workflow de punto de entrada ficticio simple para probar el workflow componible de forma aislada.
Crea un archivo en blanco llamado main.nf en el mismo directorio original-hello.
Copia el siguiente código en el archivo main.nf.
Hay dos observaciones importantes que hacer aquí:
- La sintaxis para llamar al workflow importado es esencialmente la misma que la sintaxis para llamar módulos.
- Todo lo que está relacionado con llevar las entradas al workflow (parámetro de entrada y construcción del canal) ahora se declara en este workflow padre.
Nota
Nombrar el archivo de workflow de punto de entrada main.nf es una convención, no un requisito.
Si sigues esta convención, puedes omitir especificar el nombre del archivo del workflow en tu comando nextflow run.
Nextflow buscará automáticamente un archivo llamado main.nf en el directorio de ejecución.
Sin embargo, puedes nombrar el archivo de workflow de punto de entrada de otra manera si lo prefieres.
En ese caso, asegúrate de especificar el nombre del archivo del workflow en tu comando nextflow run.
3.3. Probar que el workflow se ejecuta¶
Finalmente tenemos todas las piezas que necesitamos para verificar que el workflow componible funciona. ¡Ejecutémoslo!
Aquí ves la ventaja de usar la convención de nomenclatura main.nf.
Si hubiéramos nombrado el workflow de punto de entrada algo_mas.nf, habríamos tenido que hacer nextflow run original-hello/algo_mas.nf.
Si hiciste todos los cambios correctamente, esto debería ejecutarse hasta completarse.
Salida del comando
N E X T F L O W ~ version 25.10.4
Launching `original-hello/main.nf` [friendly_wright] DSL2 - revision: 1ecd2d9c0a
executor > local (8)
[24/c6c0d8] HELLO:sayHello (3) | 3 of 3 ✔
[dc/721042] HELLO:convertToUpper (3) | 3 of 3 ✔
[48/5ab2df] HELLO:collectGreetings | 1 of 1 ✔
[e3/693b7e] HELLO:cowpy | 1 of 1 ✔
Output: /workspaces/training/hello-nf-core/work/e3/693b7e48dc119d0c54543e0634c2e7/cowpy-COLLECTED-test-batch-output.txt
Esto significa que hemos actualizado exitosamente nuestro workflow HELLO para que sea componible.
Conclusión¶
Sabes cómo hacer un workflow componible dándole un nombre y agregando declaraciones take, main y emit, y cómo llamarlo desde un workflow de punto de entrada.
¿Qué sigue?¶
Aprende cómo injertar un workflow componible básico en la estructura base nf-core.
4. Ajustar la lógica del workflow actualizado en el workflow placeholder¶
Ahora que hemos verificado que nuestro workflow componible funciona correctamente, volvamos a la estructura base del pipeline nf-core que creamos en la sección 1. Queremos integrar el workflow componible que acabamos de desarrollar en la estructura de plantilla nf-core, para que el resultado final se vea algo así.
Entonces, ¿cómo hacemos que eso suceda? Echemos un vistazo al contenido actual del workflow HELLO en core-hello/workflows/hello.nf (la estructura base nf-core).
Las líneas destacadas definen la estructura del workflow componible: workflow HELLO {, take:, main: y emit:.
El bloque extenso entre las líneas 17–34 es más sustancial: maneja la captura de versiones de software usando topic channels, un mecanismo que nf-core está implementando en todos los pipelines en 2026.
Lo explicaremos en la Parte 4; por ahora, trátalo como código estándar que puedes dejar sin modificar.
Necesitamos agregar el código relevante del workflow componible original que desarrollamos en la sección 2.
Vamos a abordar esto en las siguientes etapas:
- Copiar los módulos y configurar las importaciones de módulos
- Dejar la declaración
takecomo está - Agregar la lógica del workflow al bloque
main - Actualizar el bloque
emit
Nota
Vamos a ignorar el bloque de captura de versiones por este primer paso. La Parte 4 explica cómo funciona.
4.1. Copiar los módulos y configurar las importaciones de módulos¶
Los cuatro procesos de nuestro workflow Hello Nextflow están almacenados como módulos en original-hello/modules/.
Necesitamos copiar esos módulos en la estructura del proyecto nf-core (bajo core-hello/modules/local/) y agregar declaraciones de importación al archivo de workflow nf-core.
Primero copiemos los archivos de módulos de original-hello/ a core-hello/:
Ahora deberías ver el directorio de módulos listado bajo core-hello/.
Contenido del directorio
Ahora configuremos las declaraciones de importación de módulos.
Estas eran las declaraciones de importación en el workflow original-hello/hello.nf:
| original-hello/hello.nf | |
|---|---|
Abre el archivo core-hello/workflows/hello.nf y transpón esas declaraciones de importación en él como se muestra a continuación.
Dos observaciones más interesantes aquí:
- Hemos adaptado el formato de las declaraciones de importación para seguir la convención de estilo nf-core.
- Hemos actualizado las rutas relativas a los módulos para reflejar que ahora están almacenados en un nivel diferente de anidamiento.
4.2. Dejar la declaración take como está¶
El proyecto nf-core tiene mucha funcionalidad preconstruida alrededor del concepto de samplesheet, que típicamente es un archivo CSV que contiene datos en columnas.
Como eso es esencialmente lo que es nuestro archivo greetings.csv, mantendremos la declaración take actual como está, y simplemente actualizaremos el nombre del canal de entrada en el siguiente paso.
El manejo de entrada se hará antes de este workflow (no en este archivo de código).
4.3. Agregar la lógica del workflow al bloque main¶
Ahora que nuestros módulos están disponibles para el workflow, podemos conectar la lógica del workflow en el bloque main.
Como recordatorio, este es el código relevante en el workflow original, que no cambió mucho cuando lo hicimos componible (solo agregamos la línea main:):
Necesitamos copiar el código que viene después de main: en la nueva versión del workflow.
Ya hay algo de código allí que tiene que ver con capturar las versiones de las herramientas que ejecuta el workflow. Vamos a dejarlo solo por ahora (nos ocuparemos de las versiones de las herramientas más tarde).
Mantendremos la inicialización ch_versions = channel.empty() en la parte superior, luego insertaremos nuestra lógica de workflow, manteniendo el código de recopilación de versiones al final.
Este orden tiene sentido porque en un pipeline real, los procesos emitirían información de versión que se agregaría al canal ch_versions a medida que el workflow se ejecuta.
Notarás que también agregamos una línea en blanco antes de main: para hacer el código más legible.
Esto se ve bien, pero todavía necesitamos actualizar el nombre del canal que estamos pasando al proceso sayHello() de greeting_ch a ch_samplesheet como se muestra a continuación, para coincidir con lo que está escrito bajo la palabra clave take:.
Ahora la lógica del workflow está correctamente conectada.
4.4. Actualizar el bloque emit¶
Finalmente, necesitamos actualizar el bloque emit para incluir la declaración de las salidas finales del workflow.
Esto concluye las modificaciones que necesitamos hacer al workflow HELLO en sí mismo. En este punto, hemos logrado la estructura general de código que nos propusimos implementar.
Conclusión¶
Sabes cómo ajustar las piezas centrales de un workflow componible en un workflow placeholder nf-core.
¿Qué sigue?¶
Aprende cómo adaptar cómo se manejan las entradas en la estructura base del pipeline nf-core.
5. Adaptar el manejo de entradas¶
Ahora que hemos integrado exitosamente nuestra lógica de workflow en la estructura base nf-core, necesitamos abordar una pieza más crítica: asegurar que nuestros datos de entrada se procesen correctamente.
La plantilla nf-core viene con un manejo de entrada sofisticado diseñado para conjuntos de datos genómicos complejos, por lo que necesitamos adaptarlo para que funcione con nuestro archivo greetings.csv más simple.
5.1. Identificar dónde se manejan las entradas¶
El primer paso es averiguar dónde se realiza el manejo de entrada.
Puede que recuerdes que cuando reescribimos el workflow Hello Nextflow para que fuera componible, movimos la declaración del parámetro de entrada un nivel arriba, en el workflow de punto de entrada main.nf.
Así que echemos un vistazo al workflow de punto de entrada main.nf de nivel superior que se creó como parte de la estructura base del pipeline:
El proyecto nf-core hace un uso intensivo de subworkflows anidados, por lo que esta parte puede ser un poco confusa al principio.
Lo que importa aquí es que hay dos workflows definidos:
CORE_HELLOes un envoltorio delgado para ejecutar el workflow HELLO que acabamos de terminar de adaptar encore-hello/workflows/hello.nf.- Un workflow sin nombre que llama a
CORE_HELLOasí como a otros dos subworkflows,PIPELINE_INITIALISATIONyPIPELINE_COMPLETION.
Aquí hay un diagrama de cómo se relacionan entre sí:
Importante, no podemos encontrar ningún código construyendo un canal de entrada en este nivel, solo referencias a un samplesheet proporcionado a través del parámetro --input.
Un poco de investigación revela que el manejo de entrada lo realiza el subworkflow PIPELINE_INITIALISATION, apropiadamente, que se importa de core-hello/subworkflows/local/utils_nfcore_hello_pipeline/main.nf.
Si abrimos ese archivo y nos desplazamos hacia abajo, llegamos a este fragmento de código:
Esta es la fábrica de canales que analiza el samplesheet y lo pasa en una forma que está lista para ser consumida por el workflow HELLO.
Nota
La sintaxis anterior es un poco diferente de lo que hemos usado anteriormente, pero básicamente esto:
es equivalente a esto:
Este código involucra algunos pasos de análisis y validación que son altamente específicos del samplesheet de ejemplo incluido con la plantilla del pipeline nf-core, que al momento de escribir esto es muy específico del dominio y no es adecuado para nuestro proyecto de pipeline simple.
5.2. Reemplazar el código del canal de entrada de la plantilla¶
La buena noticia es que las necesidades de nuestro pipeline son mucho más simples, por lo que podemos reemplazar todo eso por el código de construcción de canal que desarrollamos en el workflow Hello Nextflow original.
Como recordatorio, así se veía la construcción del canal (como se ve en el directorio de soluciones):
| solutions/composable-hello/main.nf | |
|---|---|
Así que solo necesitamos conectar eso en el workflow de inicialización, con cambios menores: actualizamos el nombre del canal de greeting_ch a ch_samplesheet, y el nombre del parámetro de params.greeting a params.input (ver línea destacada).
| core-hello/subworkflows/local/utils_nfcore_hello_pipeline/main.nf | |
|---|---|
Eso completa los cambios que necesitamos hacer para que el procesamiento de entrada funcione.
En su forma actual, esto no nos permitirá aprovechar las capacidades integradas de nf-core para la validación de esquema, pero podemos agregar eso más tarde. Por ahora, nos estamos enfocando en mantenerlo lo más simple posible para llegar a algo que podamos ejecutar exitosamente en datos de prueba.
5.3. Actualizar el perfil de prueba¶
Hablando de datos de prueba y parámetros, actualicemos el perfil de prueba para este pipeline para usar el mini-samplesheet greetings.csv en lugar del samplesheet de ejemplo proporcionado en la plantilla.
Bajo core-hello/conf, encontramos dos perfiles de prueba de plantilla: test.config y test_full.config, que están destinados a probar una muestra pequeña de datos y una de tamaño completo.
Dado el propósito de nuestro pipeline, realmente no hay sentido en configurar un perfil de prueba de tamaño completo, así que siéntete libre de ignorar o eliminar test_full.config.
Nos vamos a enfocar en configurar test.config para que se ejecute en nuestro archivo greetings.csv con algunos parámetros predeterminados.
5.3.1. Copiar el archivo greetings.csv¶
Primero necesitamos copiar el archivo greetings.csv a un lugar apropiado en nuestro proyecto de pipeline.
Típicamente los archivos de prueba pequeños se almacenan en el directorio assets, así que copiemos el archivo desde nuestro directorio de trabajo.
Ahora el archivo greetings.csv está listo para ser usado como entrada de prueba.
5.3.2. Actualizar el archivo test.config¶
Ahora podemos actualizar el archivo test.config de la siguiente manera:
| core-hello/conf/test.config | |
|---|---|
Puntos clave:
- Usando
${projectDir}: Esta es una variable implícita de Nextflow que apunta al directorio donde se encuentra el script de workflow principal (la raíz del pipeline). Usarla asegura que la ruta funcione independientemente de dónde se ejecute el pipeline. - Rutas absolutas: Al usar
${projectDir}, creamos una ruta absoluta, lo cual es importante para datos de prueba que se envían con el pipeline. - Ubicación de datos de prueba: Los pipelines nf-core típicamente almacenan datos de prueba en el directorio
assets/dentro del repositorio del pipeline para archivos de prueba pequeños, o referencian conjuntos de datos de prueba externos para archivos más grandes.
Y ya que estamos en eso, ajustemos los límites de recursos predeterminados para asegurar que esto se ejecutará en máquinas muy básicas (como las VMs mínimas en Github Codespaces):
Esto completa las modificaciones de código que necesitamos hacer.
5.4. Ejecutar el pipeline con el perfil de prueba¶
Eso fue mucho, ¡pero finalmente podemos intentar ejecutar el pipeline!
Ten en cuenta que tenemos que agregar --validate_params false a la línea de comando porque no configuramos la validación todavía (eso vendrá más tarde).
Si has hecho todas las modificaciones correctamente, debería ejecutarse hasta completarse.
Salida del comando
N E X T F L O W ~ version 25.10.4
Launching `core-hello/main.nf` [condescending_allen] DSL2 - revision: b9e9b3b8de
Input/output options
input : /workspaces/training/hello-nf-core/core-hello/assets/greetings.csv
outdir : core-hello-results
Institutional config options
config_profile_name : Test profile
config_profile_description: Minimal test dataset to check pipeline function
Generic options
validate_params : false
trace_report_suffix : 2025-11-21_07-29-37
Core Nextflow options
runName : condescending_allen
containerEngine : docker
launchDir : /workspaces/training/hello-nf-core
workDir : /workspaces/training/hello-nf-core/work
projectDir : /workspaces/training/hello-nf-core/core-hello
userName : root
profile : test,docker
configFiles : /workspaces/training/hello-nf-core/core-hello/nextflow.config
!! Only displaying parameters that differ from the pipeline defaults !!
------------------------------------------------------
executor > local (1)
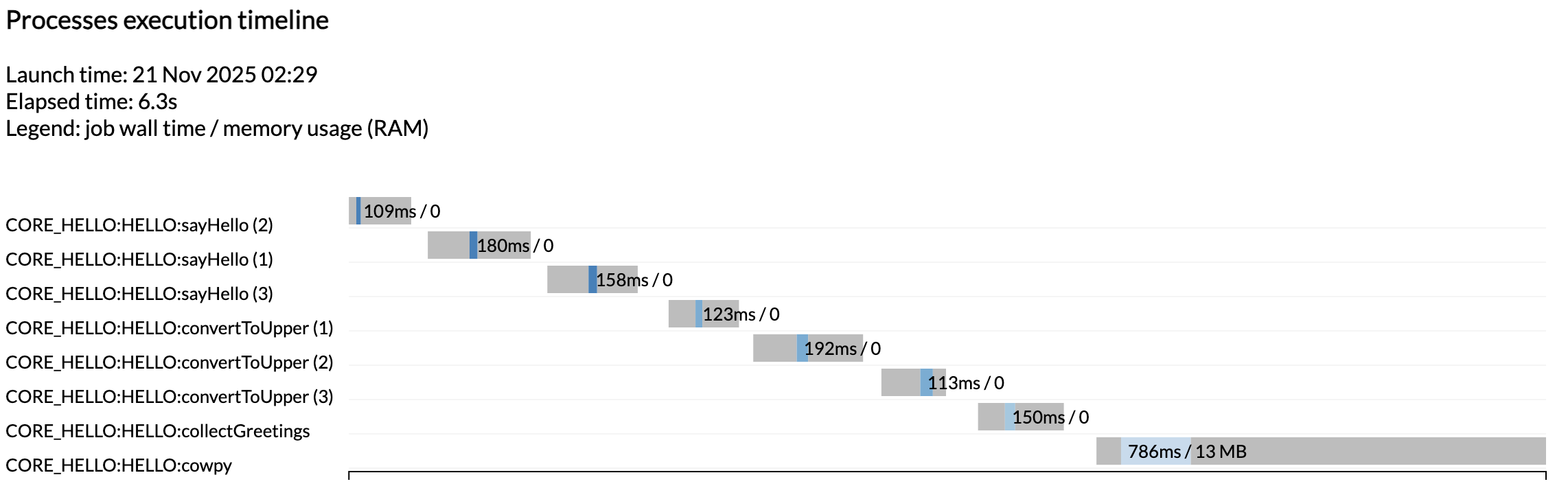
[ed/727b7e] CORE_HELLO:HELLO:sayHello (3) [100%] 3 of 3 ✔
[45/bb6096] CORE_HELLO:HELLO:convertToUpper (3) [100%] 3 of 3 ✔
[81/7e2e34] CORE_HELLO:HELLO:collectGreetings [100%] 1 of 1 ✔
[96/9442a1] CORE_HELLO:HELLO:cowpy [100%] 1 of 1 ✔
-[core/hello] Pipeline completed successfully-
Como puedes ver, esto produjo el resumen típico de nf-core al inicio gracias al subworkflow de inicialización, y las líneas para cada módulo ahora muestran los nombres completos PIPELINE:WORKFLOW:module.
5.5. Encontrar las salidas del pipeline¶
La pregunta ahora es: ¿dónde están las salidas del pipeline? Y la respuesta es bastante interesante: ahora hay dos lugares diferentes donde buscar los resultados.
Como puede que recuerdes de antes, nuestra primera ejecución del workflow recién creado produjo un directorio llamado core-hello-results/ que contenía varios reportes de ejecución y metadatos.
Contenido del directorio
core-hello-results
└── pipeline_info
├── execution_report_2025-11-21_04-47-18.html
├── execution_report_2025-11-21_07-29-37.html
├── execution_timeline_2025-11-21_04-47-18.html
├── execution_timeline_2025-11-21_07-29-37.html
├── execution_trace_2025-11-21_04-47-18.txt
├── execution_trace_2025-11-21_07-29-37.txt
├── hello_software_versions.yml
├── params_2025-11-21_04-47-13.json
├── params_2025-11-21_07-29-41.json
├── pipeline_dag_2025-11-21_04-47-18.html
└── pipeline_dag_2025-11-21_07-29-37.html
1 directory, 12 files
Ves que obtuvimos otro conjunto de reportes de ejecución además de los que obtuvimos de la primera ejecución, cuando el workflow era solo un placeholder. Esta vez ves todas las tareas que se ejecutaron como se esperaba.
Nota
Una vez más, las tareas no se ejecutaron en paralelo porque estamos ejecutando en una máquina minimalista en Github Codespaces. Para ver que se ejecuten en paralelo, intenta aumentar la asignación de CPU de tu codespace y los límites de recursos en la configuración de prueba.
Eso es genial, ¡pero nuestros resultados reales del pipeline no están ahí!
Aquí está lo que pasó: no cambiamos nada de los módulos en sí, por lo que las salidas manejadas por las directivas publishDir a nivel de módulo todavía van a un directorio results como se especificó en el pipeline original.
Contenido del directorio
results
├── Bonjour-output.txt
├── COLLECTED-test-batch-output.txt
├── COLLECTED-test-output.txt
├── cowpy-COLLECTED-test-batch-output.txt
├── cowpy-COLLECTED-test-output.txt
├── Hello-output.txt
├── Hola-output.txt
├── UPPER-Bonjour-output.txt
├── UPPER-Hello-output.txt
└── UPPER-Hola-output.txt
0 directories, 10 files
Ah, ahí están, mezclados con las salidas de ejecuciones anteriores del pipeline Hello original.
Si queremos que estén organizados ordenadamente como lo estaban las salidas del pipeline demo, necesitaremos cambiar cómo configuramos las salidas para ser publicadas. Te mostraremos cómo hacer eso más adelante en este curso de entrenamiento.
¡Y ahí lo tienes! Puede parecer mucho trabajo para lograr el mismo resultado que el pipeline original, pero obtienes todos esos reportes hermosos generados automáticamente, y ahora tienes una base sólida para aprovechar las características adicionales de nf-core, incluyendo la validación de entrada y algunas capacidades ingeniosas de manejo de metadatos que cubriremos en una sección posterior.
Conclusión¶
Sabes cómo convertir un pipeline regular de Nextflow en un pipeline de estilo nf-core usando la plantilla nf-core. Como parte de eso, aprendiste cómo hacer un workflow componible, y cómo identificar los elementos de la plantilla nf-core que más comúnmente necesitan ser adaptados al desarrollar un pipeline de estilo nf-core personalizado.
¿Qué sigue?¶
¡Toma un descanso, fue un trabajo duro! Cuando estés listo, continúa con Parte 3: Usar un módulo nf-core para aprender cómo aprovechar módulos mantenidos por la comunidad del repositorio nf-core/modules.